Apriori算法+Partition算法+Hash算法+Sample方法+Close算法
本文共 1289 字,大约阅读时间需要 4 分钟。
Apriori算法: 几个概念:
项目集Item在数据集D上的支持度=包含Item的事务在D中所占的百分比 若项目集Item的支持度大于用户指定的最小支持度min_sup,则Item为频繁项目集。 support(Item) = P(Item)= |{T: Item∈T,T∈D}|/|D|×100% 关联规则的支持度为 support(X ∈Y) = support(X∪Y) 关联规则的可信度为 conf(X ∈Y) =support(X∪Y)/support(X) 在D上满足最小支持度min-sup和最小可信度min-conf的关联规则称为强关联规则 Apriori 性质 如果项目集X是频繁项目集,则它的所有非空子集都是频繁项目集如{I1,I2}频繁,则{I1}频繁。 如果项目集X不是频繁项目集,则它的所有超集都不是频繁项目集如{I1}不频繁,则{I1,I2}不频繁。 Apriori算法的主要步骤:1.连接 2.剪枝 3.验证 4.回到1直到没有频繁集生成。 示例如下:

 Apriori算法存在的问题:多次扫描数据库,如果数据库庞大,算法效率会很低,可能会产生庞大的候选集。 分区方法(Partition): 1 如果一个项集X在站点Si上是局部频繁项,则X的所有子集在站点Si上也是局部频繁项。 2 如果一个项集X是全局频繁项,则至少存在一个站点Si,X在Si上是局部频繁项
Apriori算法存在的问题:多次扫描数据库,如果数据库庞大,算法效率会很低,可能会产生庞大的候选集。 分区方法(Partition): 1 如果一个项集X在站点Si上是局部频繁项,则X的所有子集在站点Si上也是局部频繁项。 2 如果一个项集X是全局频繁项,则至少存在一个站点Si,X在Si上是局部频繁项 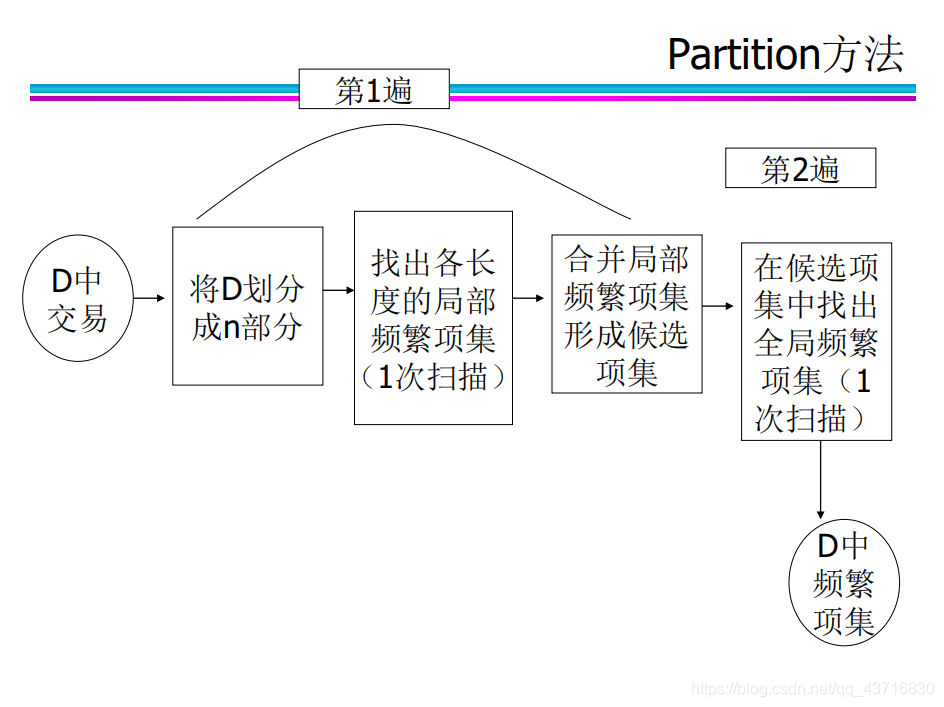 散列方法(Hash) 每对项目最多只能放在一个特定的桶中,对每个桶中的项目子集进行测试,减少候选集生成的代价
散列方法(Hash) 每对项目最多只能放在一个特定的桶中,对每个桶中的项目子集进行测试,减少候选集生成的代价 
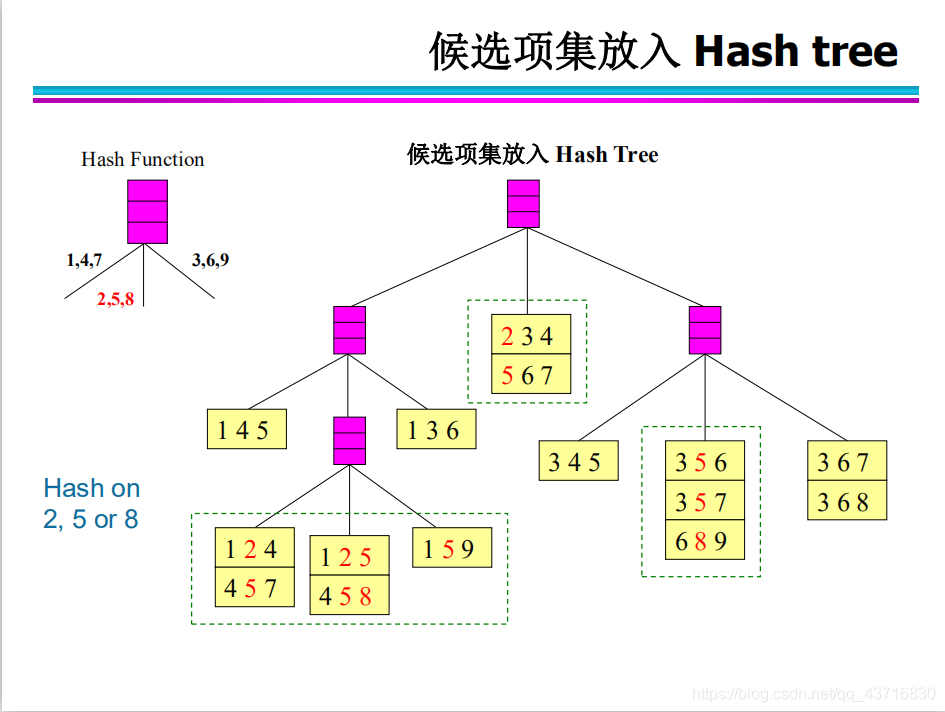
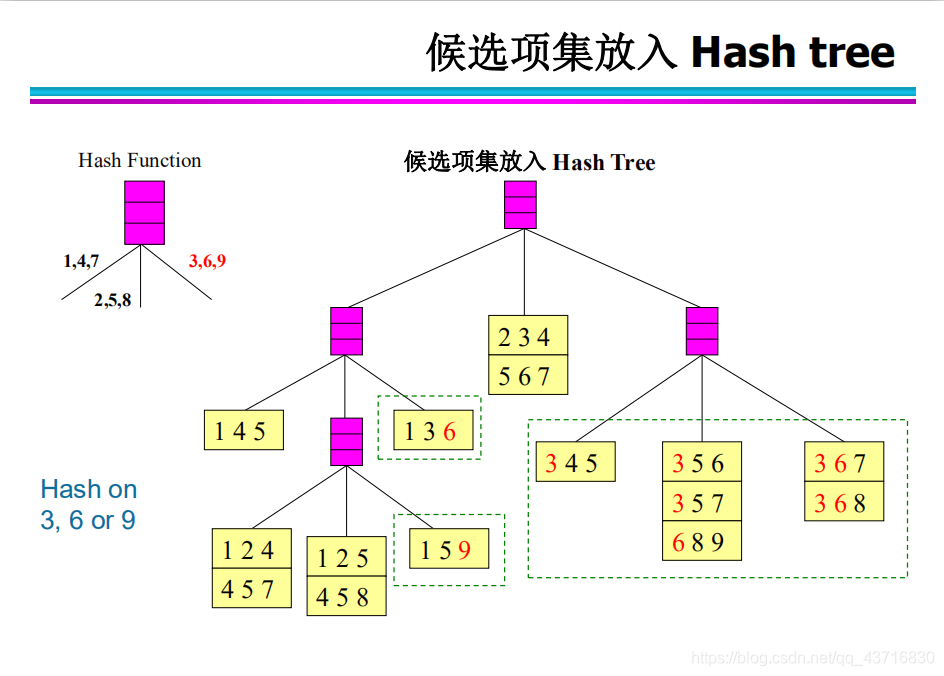
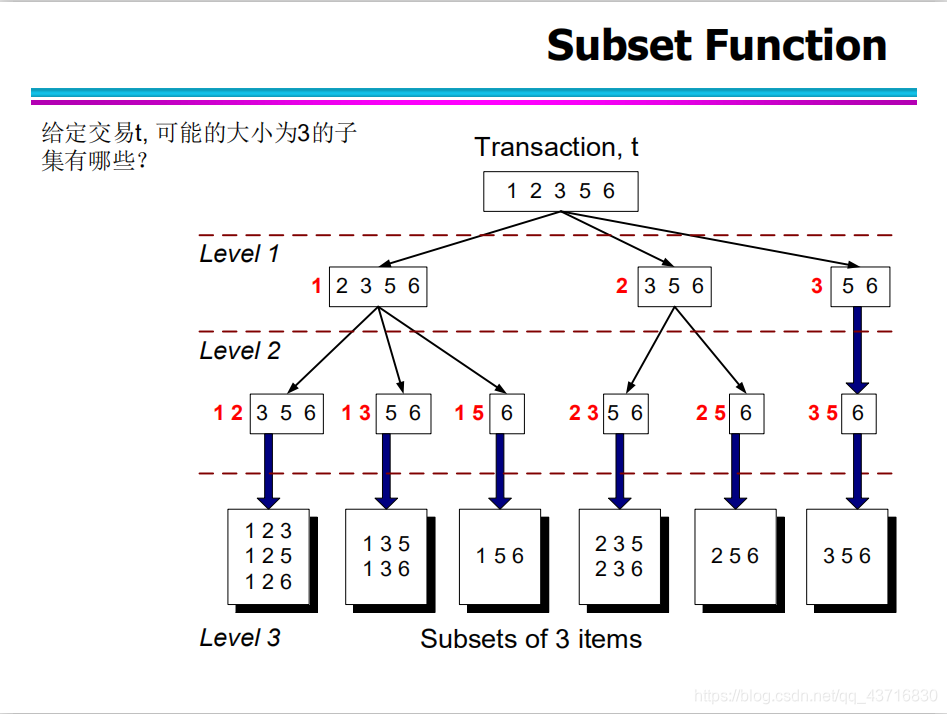
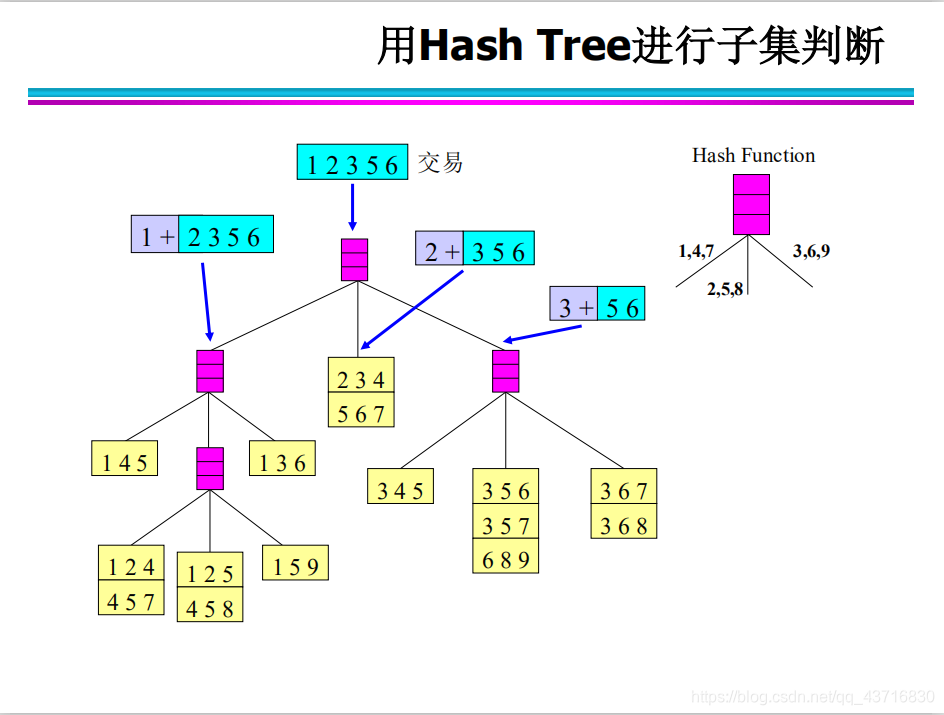
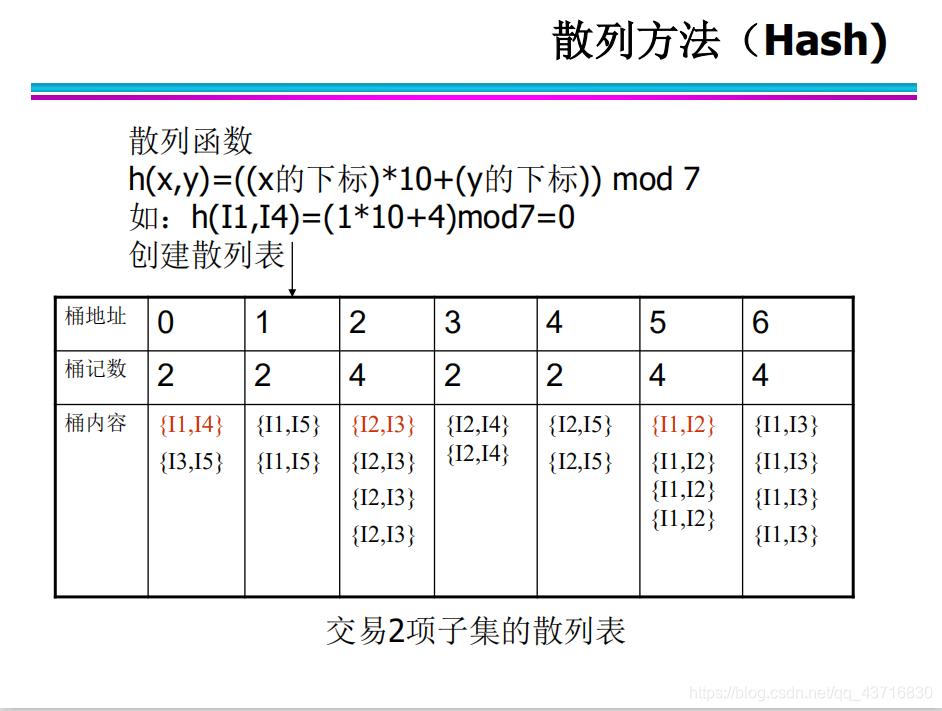 Hash结构的作用——减少比较次数
Hash结构的作用——减少比较次数 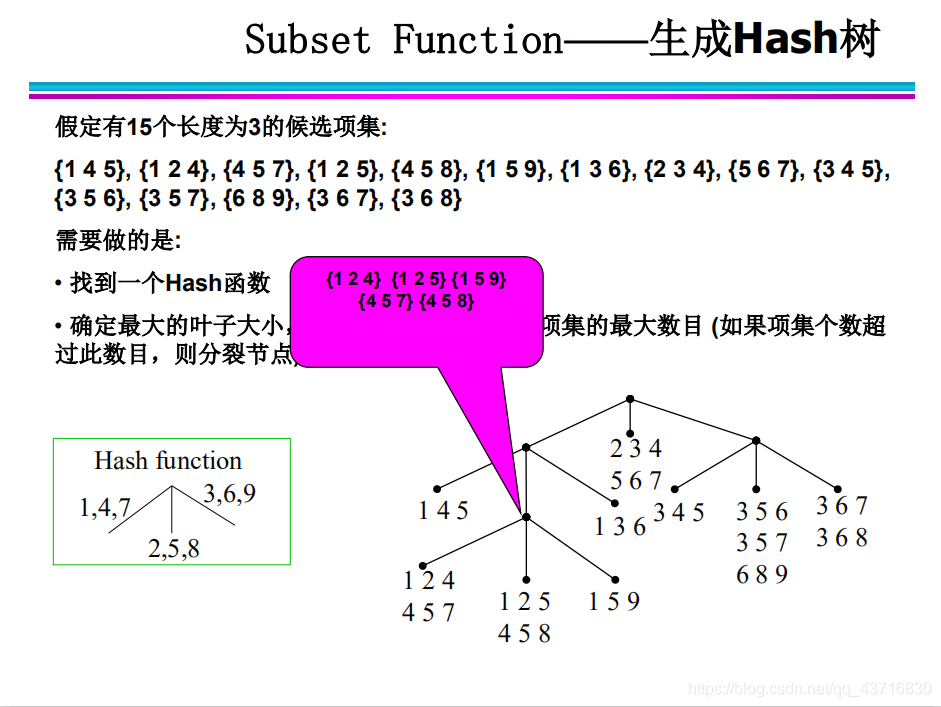
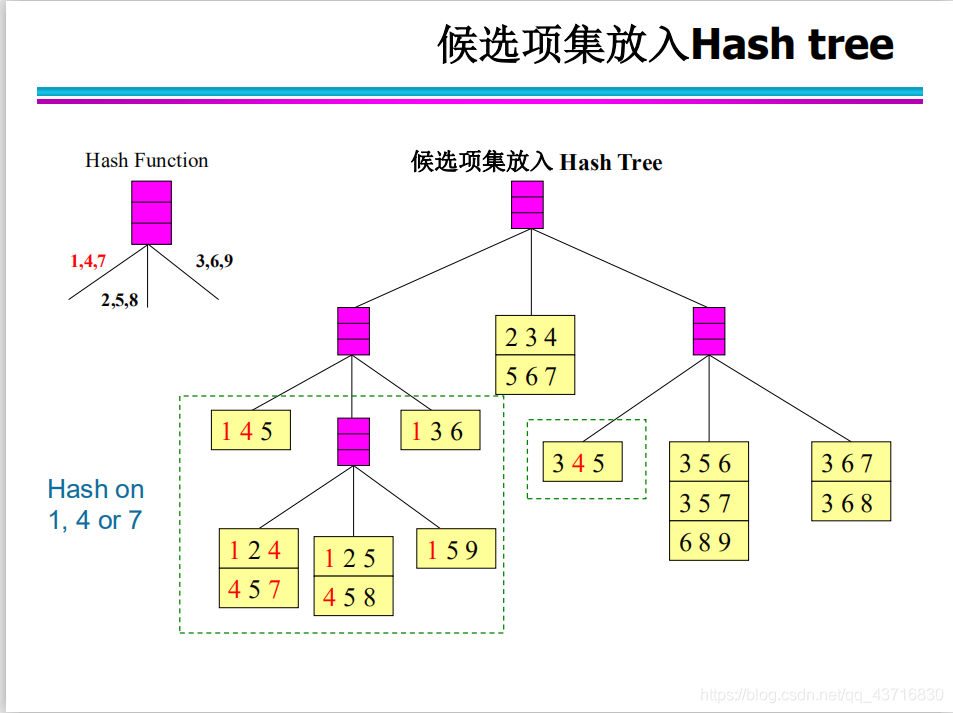
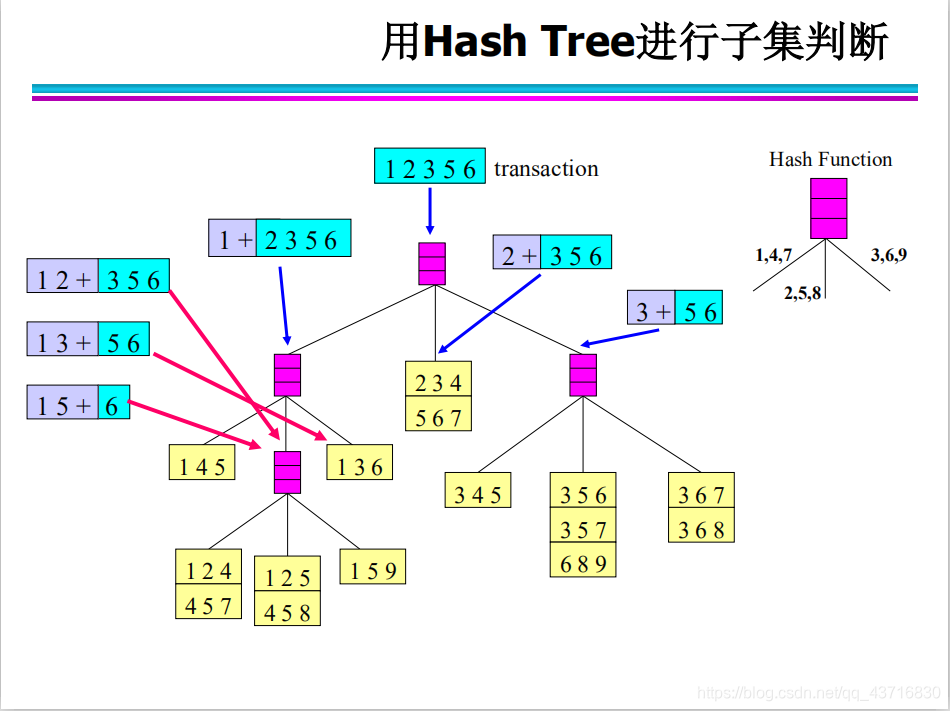
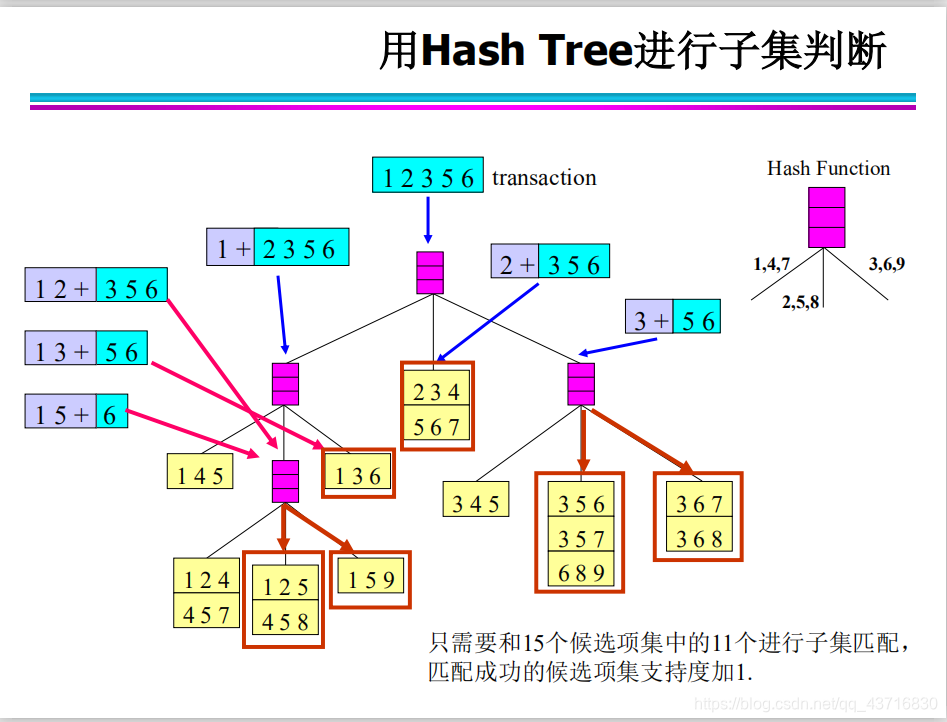 抽样方法(Sample): 使用数据库中的一些抽样数据得到一些可能成立的规则,然后用数据库的剩余部分来验证这些规则是否成立。抽样数据的选取结果偏差问题(数据扭曲) Close算法——闭合的项集 如果一个项目集的每个超集的支持度都小于它的支持度,则该项目集是闭合的。 如果一个项集是频繁项集,而它的每个超集都不是频繁的,则该项集是最大的频繁项集。
抽样方法(Sample): 使用数据库中的一些抽样数据得到一些可能成立的规则,然后用数据库的剩余部分来验证这些规则是否成立。抽样数据的选取结果偏差问题(数据扭曲) Close算法——闭合的项集 如果一个项目集的每个超集的支持度都小于它的支持度,则该项目集是闭合的。 如果一个项集是频繁项集,而它的每个超集都不是频繁的,则该项集是最大的频繁项集。 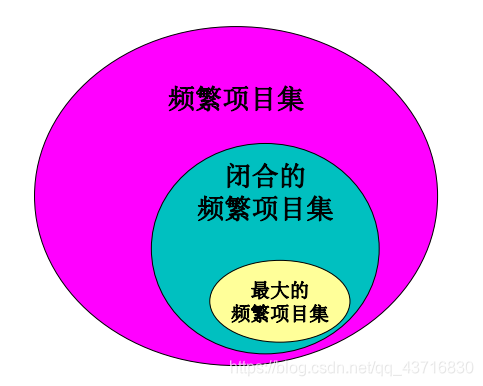 Close算法的原理 频繁(闭合)项目集的所有(闭合)子集一定是频繁的; 非频繁(闭合)项目集的所有(闭合)超集一定是非频繁的。 关键步骤: – 求产生式(连接、非频繁子集剪枝、利用闭合剪枝) – 求闭合(交易项集的交集,同时得出支持度) – 验证
Close算法的原理 频繁(闭合)项目集的所有(闭合)子集一定是频繁的; 非频繁(闭合)项目集的所有(闭合)超集一定是非频繁的。 关键步骤: – 求产生式(连接、非频繁子集剪枝、利用闭合剪枝) – 求闭合(交易项集的交集,同时得出支持度) – 验证 
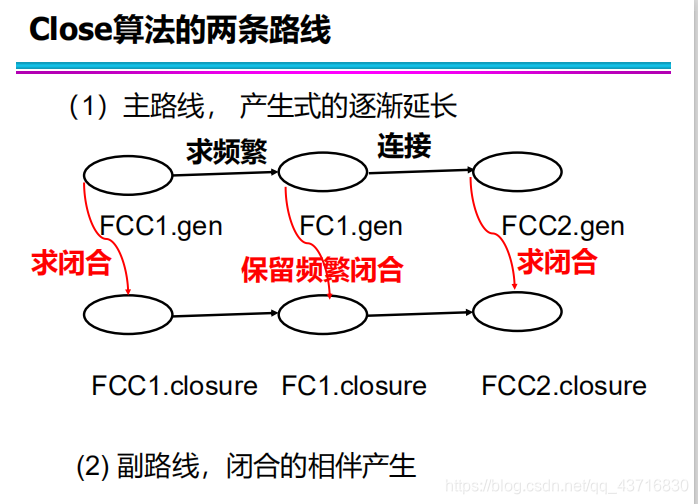 例如,最小支持数为2时 FC1.gen={A,B,C,D,E} 闭合项集: FC1.closure={A,B,C,BD,ABE} 按照Apriori算法,将FC1.gen进行连接,得到 FCC2 .gen= {AB,AC,AD,AE,BC,BD,BE,CD,CE,DE} 利用FC1.closure对FCC2.gen剪枝: FC1.closure={A,B,C,BD,ABE} FCC2 .gen ={AB,AC,AD,BC,CD,CE,DE} FC2 .gen ={AB,AC, BC,BD}。 …… 最后求所有闭合的并集,再把并集的所有分解都加入集合中即为所有频繁项集 Close算法的效率体现在:频繁闭合项目集通常比所有的频繁项目集少很多
例如,最小支持数为2时 FC1.gen={A,B,C,D,E} 闭合项集: FC1.closure={A,B,C,BD,ABE} 按照Apriori算法,将FC1.gen进行连接,得到 FCC2 .gen= {AB,AC,AD,AE,BC,BD,BE,CD,CE,DE} 利用FC1.closure对FCC2.gen剪枝: FC1.closure={A,B,C,BD,ABE} FCC2 .gen ={AB,AC,AD,BC,CD,CE,DE} FC2 .gen ={AB,AC, BC,BD}。 …… 最后求所有闭合的并集,再把并集的所有分解都加入集合中即为所有频繁项集 Close算法的效率体现在:频繁闭合项目集通常比所有的频繁项目集少很多 转载地址:http://hngwi.baihongyu.com/
你可能感兴趣的文章
objdump的使用方法
查看>>
编译错误处理noproguard.classes-with-local.dex已杀死
查看>>
LTE - CSFB技术
查看>>
GSM链路层信令协议
查看>>
技术道德
查看>>
“需求为王”才是根本
查看>>
高效率的危害
查看>>
寻找边缘性创新
查看>>
让创意瞄准市场
查看>>
高效经理人应具有的八个重要习惯
查看>>
优秀的领导者能读懂人才
查看>>
大智若愚也是领导力
查看>>
android如何编译MTK的模拟器
查看>>
android如何添加AP中要使用的第三方JAR文件
查看>>
利用sudo命令为Ubuntu分配管理权限
查看>>
Ubuntu下几个重要apt-get命令用法与加速UBUNTU
查看>>
Ubuntu中网页各种插件安装命令
查看>>
使用tar命令备份Ubuntu系统
查看>>
ubuntu flash 文字乱码解决方案
查看>>
在ubuntu中运行exe文件
查看>>